
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- 뉴비톤
- 스터디 잼
- Community Day
- CSIP
- API
- re:Invent
- Tensorflow 2.0
- 오픈소스해커톤
- 코딩테스트
- Conference
- SageMaker
- Speech
- kakao
- BOAZ
- Open Hack
- GDG Campus
- OPENHACK
- 머신러닝
- seq2seq
- ainize
- Ground Truth
- Backend.AI
- SW중심대학
- aws
- Qwik Start
- gcp
- 해커톤
- rl
- entity
- 구글스타트업캠퍼스
- Today
- Total
pizzaplanet
[참관후기] 제9회 BOAZ BIGDATA CONFERENCE(2) 본문
3주만에 Part 2를 쓰는 듯 하다.
큰 제목을 누르면 발표 영상으로 이동합니다.
AIRBnB : Aspect in Review 비교&분석
Data
도시 = 서울, 부산, 제주, 서귀포, 강릉, 전주, 대전, 대구, 광주, 여수
방 고유 번호 Listing ID 수집
지역별 방 수 = 32,958
지역별 리뷰 수 = 628,095
1. 전처리
- 40여개 언어 혼재
- 파파고 번역기 이용 (특수문자 포함 리뷰는 파파고 번역과정시 에러나서 2600개 제외)
- 전처리가 쉬운 영어로 번역. 약 628,000 리뷰로 프로젝트 진행.
- 불필요한 기호 제거 (단, . ! ? 와 같은 문장 끝 정보 기호는 남김)
- 정확한 문장 Tokenizing을 위해 정규표현식으로 띄어쓰기 보정
- 너무 짧은 문장, 리뷰가 없는 방 제거
- Tokenizing(NLTK)
- Tokenizing 후 품사 Tagging
- 명사, 형용사, 동사, 부사만 뽑고 고유명사('NNP')는 선택적으로 제거
- 품사별 Lemmatization(표제어 추출) 진행
- 모든 단어 소문자화
- 불용어 제거(Python NLTK의 stopwords 사용. 분석 진행하며 불필요한 단어 업데이트하며 진행)
2. 전처리 목적
리뷰를 요약하는 단어 추출.
Model
1. LDA(Latent Dirichlet Allocation) : Topic modeling
Target : 리뷰를 쓸 때, 중요하게 생각하는 주제
LDA 가정
- 한 리뷰에는 여러 주제 포함될 수 있음
- 주제에 여러 개의 단어 포함될 수 있음
- 리뷰에 사용된 단어 각각은 어떤 주제에 포함된다.
LDA란
Unsupervised generative topic model.
주로 문서 컬렉션(corpus)을 표현하는 방법을 generative한 방법으로 찾는 것이며, 주제 분류나 문서 간 유사도 계산에 많이 쓰인다.
결과
- 9개 지역에 대해 비슷한 것으로 묶다 보니 해안, 내륙으로 나뉘어짐.
- 해안과 내륙에 따라 지역 별 주제 분포의 차이를 보임.
- LDA를 사용했기에 이때 단어를 보고 어떤 topic 인지 명시를 해야 하는 단점이 있었음
- 토픽 별 단어 분포도를 보며 주제들을 파악함.
ex> ★★★★☆
사진처럼 정말 깨끗했습니다. 바로 해운대 백사장이 있어 산책하기 좋았고 주변 편의 시설 좋았습니다. 하지만 가격이 비싸서 아쉬웠습니다.
별점 4점
= 청결도 x 4 + 위치 x 5 + 가격 x 2
= 0.5 x 4 + 0.35 x 5 + 0.125 x 2
4, 5, 2 => Aspect Rate(Sd)
컬러들 => Aspect Weight(αd)
LARA란
LDA 기반으로 만들어진 모델이라 LDA 프레임과 비슷하다.
Aspect Rate(S)와 Aspect Weight(α)를 통해 총 별점을 추정 가능하다.
역으로 총 별점을 알고 있고 W(Word)를 가지고 있으면 R과 S를 추정할 수 있다.
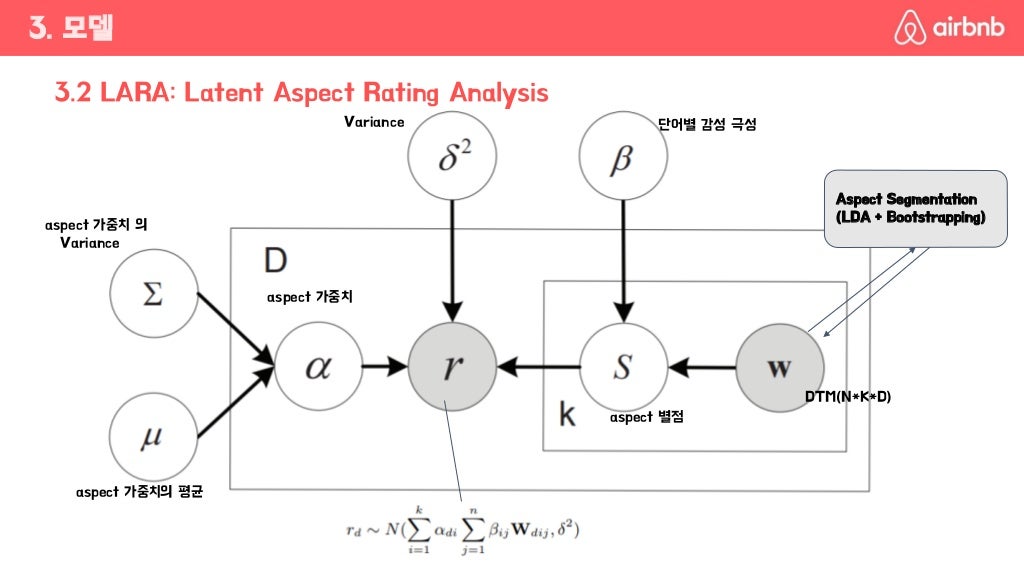
결과
프레임 밖의 4가지(외부변수)들을 가지고 Aspect Rate(S)와 Aspect Weight(α)를 추정하는 과정에서 수렴하지 않음.
결국 모티브만 가지고 Aspect Rate(S)와 Aspect Weight(α)를 나름대로 줌
3. Elastic Net - 감정사전 구축, 다른 방법으로는 각 주제에 대한 사람들의 생각과 감정을 알 수 없을까?
감정사전이란, 단어에 극성이 있음을 말해주는 것. best는 긍정이라고 하는 것처럼.
이때 문제점이 있다. 저렴하다의 경우 '가격이 저렴하다'는 긍정이나, '맛이 저렴하다'는 부정이다.
이처럼 같은 단어라도 도메인에 따라 극성이 바뀌게 되므로 숙소에 따른 감성사전 구축의 필요성을 느낌.
Elastic Net를 이용하여 에어비엔비 감성사전을 직접 구축함.
Elastic Net란
'데이터 관측치 수에 비해 변수의 수가 많아질 경우 변수간 강한 상관 관계로 과적합 발생 -> 모델 해석 어려워짐 및 예측력 저하' 라는 부분을 보정한 모델.
자동으로 변수를 선택을 해주어 감성점수를 만듦
DTM(document term matrix) - 어떤 리뷰에 단어들의 빈도수(x)와 별점(y)로 회귀를 돌려 회귀계수 베타가 개별의 단어 감정점수라고 생각하여 구축한 감정사전.

결과
빈도수 10 이상만 추출하여 412개 유의미 단어 추출.
Modelling
도메인에 대하여 구축 했지만 도메인의 Aspect별로 감정이 다를 수 있다 생각해여 Aspect별로 word에 가중치를 직접 부여
슬라이드에서는 결과가 11.4, 8 이지만 실제론 MinMax를 통해 0~1 값으로 만듦
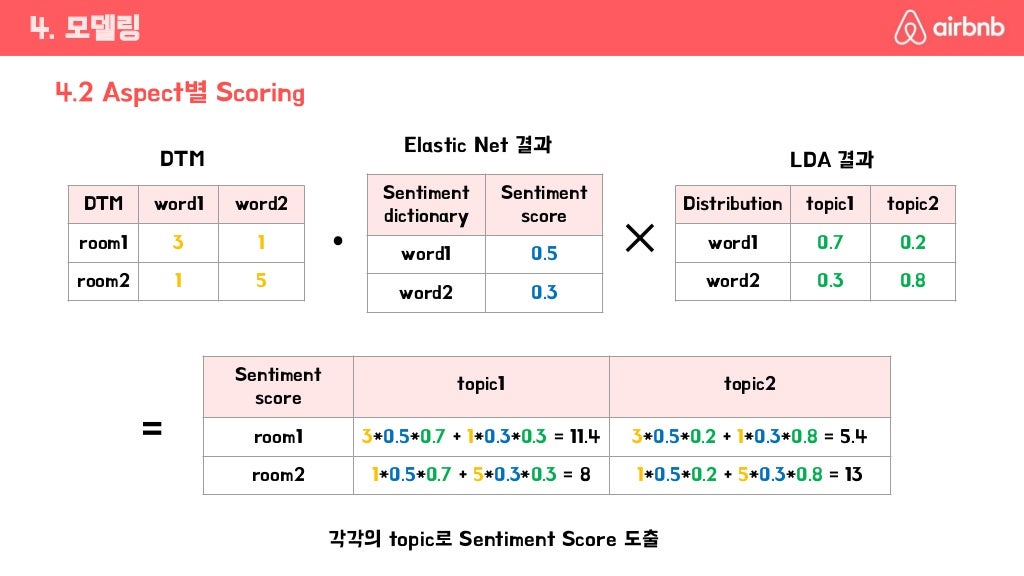
Aspect별 Scoring
돌려본 결과 예측 결과가 Good, Bad Case 둘 다 있었음
의의
- 별점과 텍스트만으로 세부 별점 도출 가능
- 본인의 선호하는 aspect를 기준으로 중요도 부여 가능
- 방 별 상대적인 aspect별 별점 부여
한계
- 긍정적 리뷰가 대다수인 데이터 불균형
- 감정사전 직접 구축의 어려움
- 평가기준 없어 성능 평가 어려움
'Participation' 카테고리의 다른 글
| [참관후기] AI Tech Talk For Devs (0) | 2019.02.17 |
|---|---|
| [참관후기] 제9회 BOAZ BIGDATA CONFERENCE(3) (0) | 2019.02.17 |
| [참관후기] 제9회 BOAZ BIGDATA CONFERENCE(1) (0) | 2019.01.27 |
| 2018 데이터야놀자 X LittleBigData 발표 후기 (0) | 2018.10.30 |
| 2018 SW중심대학 Open Source Hackathon - Openhack (1) | 2018.09.11 |


