
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- seq2seq
- entity
- Ground Truth
- API
- 코딩테스트
- Qwik Start
- Conference
- 구글스타트업캠퍼스
- SageMaker
- gcp
- 머신러닝
- BOAZ
- Tensorflow 2.0
- OPENHACK
- Community Day
- 오픈소스해커톤
- re:Invent
- aws
- rl
- 해커톤
- Open Hack
- Speech
- SW중심대학
- 뉴비톤
- CSIP
- Backend.AI
- 스터디 잼
- kakao
- ainize
- GDG Campus
- Today
- Total
pizzaplanet
[참관후기] PyCon 2019 본문
[TOC]
PyCon Korea 2019
PyCon 2019 참관기를 정리합니다. 듣고싶었으나 놓친 트랙도 ppt를 참고하여 정리하였습니다.
시간복잡도로 살펴보는 파이썬 내장자료형의 효율적인 활용 | 슬라이드
연사자 : 강대성 / 현)피플펀드컴퍼니 기술고문
트랙 소개
mutable / immutable 의 특성을 이해하고 잘못 쓰지 않도록 합니다.
내장 자료형의 시간 복잡도를 resize를 중심으로 다룹니다. - LIST, DICT
최적화되어 있지만 Python에서 느린 부분을 어떻게 개선할지 살펴봅니다.
mutable / immutable의 이해
immutable: 생성 후 변하지 않음(tuple. string, byte, frozen set)
mutable: 생성 후 변할 수 있음(list, dictionary, set)
mutable / immutable concat 비교
static PyObject *
tupleconcat(PyTupleObject *a, PyObject *bb)
{
Py_ssize_t size;
Py_ssize_t i;
PyObject **src, **dest;
PyTupleObject *np;
if (Py_SIZE(a) == 0 && PyTuple_CheckExact(bb)) { // a size == 0 --> bb 자체를 반환
Py_INCREF(bb);
return bb;
}
...
#define b ((PyTupleObject *)bb)
if (Py_SIZE(b) == 0 && PyTuple_CheckExact(a)) { // bb size == 0 --> a자체를 반환
Py_INCREF(a);
return (PyObject *)a;
}
...
}>>> a = (1, 2)
>>> b = ()
>>> c = a + b
>>> id(a)
4355020800
>>> id(c)
4355020800- tuple concat은 두 tuple 중 하나가 비었으면 비지 않은 tuple을 반환함
static PyObject *
list_concat(PyListObject *a, PyObject *bb)
...
#define b ((PyListObject *)bb)
if (Py_SIZE(a) > PY_SSIZE_T_MAX - Py_SIZE(b))
return PyErr_NoMemory();
//a, b 중 size가 0이던 말던 상관 없이 무조건 a+b 만큼 size 할당
size = Py_SIZE(a) + Py_SIZE(b);
np = (PyListObject *) list_new_prealloc(size);
if (np == NULL) {
return NULL;
}
src = a->ob_item;
dest = np->ob_item;
// a + b를 할당할 np에 a, b를 순차적으로 할당
for (i = 0; i < Py_SIZE(a); i++) {
PyObject *v = src[i];
Py_INCREF(v);
dest[i] = v;
}
src = b->ob_item;
dest = np->ob_item + Py_SIZE(a);
for (i = 0; i < Py_SIZE(b); i++) {
PyObject *v = src[i];
Py_INCREF(v);
dest[i] = v;
}
Py_SIZE(np) = size;
return (PyObject *)np;
#undef b
}>>> a = (1, 2)
>>> b = ()
>>> c = a + b
>>> id(a)
4355020800
>>> id(c)
4355020904- list는 하나가 빈 list여도 복붙한다. 이것이 immutable과 mutable 차이
list extend
static PyObject *
list_extend(PyListObject *self, PyObject *iterable)
/*[clinic end generated code: output=630fb3bca0c8e789 input=9ec5ba3a81be3a4d]*/
{
PyObject *it; /* iter(v) */
Py_ssize_t m; /* size of self */
Py_ssize_t n; /* guess for size of iterable */
Py_ssize_t mn; /* m + n */
Py_ssize_t i;
PyObject *(*iternext)(PyObject *);
...
n = PyObject_LengthHint(iterable, 8);
m = Py_SIZE(self);
if (m > PY_SSIZE_T_MAX - n) {
...
}
else { // resize 발생
mn = m + n;
/* Make room. */
if (list_resize(self, mn) < 0)
goto error;
/* Make the list sane again. */
Py_SIZE(self) = m;
}
/* Run iterator to exhaustion. */
for (;;) {
PyObject *item = iternext(it);
...
if (Py_SIZE(self) < self->allocated) { // 공간 충분하면 그냥 뒤에 붙임
/* steals ref */
PyList_SET_ITEM(self, Py_SIZE(self), item);
++Py_SIZE(self);
...
}- resize*를 하는 경우: O(N+M) / (N은 원래 갯수, M은 extend에 추가된 갯수)
- resize를 안하는 경우: O(M)
static int
list_resize(PyListObject *self, Py_ssize_t newsize)
{
...
if (allocated >= newsize && newsize >= (allocated >> 1)) {
assert(self->ob_item != NULL || newsize == 0);
Py_SIZE(self) = newsize;
return 0;
}
/* This over-allocates proportional to the list size, making room
* for additional growth. The over-allocation is mild, but is
* enough to give linear-time amortized behavior over a long
* sequence of appends() in the presence of a poorly-performing
* system realloc().
* The growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
* Note: new_allocated won't overflow because the largest possible value
* is PY_SSIZE_T_MAX * (9 / 8) + 6 which always fits in a size_t.
*/
...
}- list growth pattern is: 0, 4, 8, 16, 25, 35, 46, 58, 72, 88, ...
list는 list growth pattern에 따라 item 1개만 할당 받아도 4개의 공간을 할당한다. item이 5개라면 8개의 공간을 할당 받고, item이 47개면 58개의 공간을 할당 받는다. item이 4개인 상태에서 list.extend(some)을 하게 되면 공간을 8개로 확장시키며 이를 resize라 한다.
list pop
pop의 프로세스
- list_pop_impl(PyListObject *self, Py_ssize_t index)
- list_ass_slice(self, index, index+1, (PyObject *)NULL)
- memmove(&item[ihigh+d], &item[ihigh], tail); // 엄청난 move --> O(N)
list append
list의 사이즈가 큰 상태에서 append 할수록 resize시 속도저하가 커진다.
- resize*를 하는 경우: O(1)
- resize를 안하는 경우: O(N)
이 때 공간을 미리 할당하여 resize로 인한 속도 저하 방지할 수 있다.
a = [None] * N
for i in range(N):
a[i] = i마무리하며
위는 평소에 신경쓰는 것보다 크리티컬한 문제가 생겼을 때 곱씹는 것이 효율적이다.
파이썬으로 구현하는 최적화 알고리즘 | 슬라이드
연사자 : 차지원
트랙 소개
최적화 알고리즘'은 주어진 상황에서 가장 최적의 해를 구하는 문제풀이 방법입니다. 문제풀이 과정에서 주어진 상황과 목표를 수식으로 표현하고 계산하기 때문에 다양한 수치해석 라이브러리를 사용합니다. 연산과정의 복잡성, 연산속도 등의 문제로 시중에서 제공되는 라이브러리는 꽤 한정적이며 상용 라이브러리는 C, C++에 특화되어있습니다. 저도 C#으로 유료 최적화 라이브러리를 사용해왔습니다. 스타트업에 취직 후에는 오픈소스 파이썬 라이브러리를 활용해야하는 상황에 놓였었습니다. TensorFlow, Pytorch와 달리 최적화 알고리즘 관련 파이썬 라이브러리에 대한 한글자료가 부족하여 많은 시행착오를 겪었습니다. 그때의 경험을 토대로 본 발표를 준비하고자 합니다. 발표내용은 다음과 같습니다. 1. 파이썬에서 활용 가능한 최적화 라이브러리 소개(Google OR-Tools, GLPK 등) 2. 라이브러리 설치/적용방법, Trouble shooting 공유 3. 구현 예제기존 파이콘 발표내용 중에서도 '최적화 라이브러리'를 심도있게 소개하는 내용이 없었고, 알고리즘이 적용될수 있는 분야가 다양하므로 본 발표가 Pycon과 Python 유저들에게 도움이 되길 바랍니다.
최적화, Optimization
최적화 : 한정된 자본으로 최대한의 수익을 내는 것
최적화 문제는 목적함수와 제약함수로 나뉜다.
- 목적함수
- 내 문제 상황에서 최적화하고 싶은 목표
- 비용의 최소화 또는 수익의 최대화
- 그리고 그걸 해내기 위한 결정변수 x1, x2
- 제약함수
- 내 문제상황에서 반드시 만족시켜야 할 조건들
- 예산 범위, 반드시 조달해야하는 자재의 최소 수량
- 등호제약조건 또는 부등호제약조건으로 수식화
변수, 계수, 상수
- 내 문제상황을 구성한 요소들
- 변수) 구입할 제품 수량
- 상수) 자재 가격
- 상수, 이진변수, 정수, 실수인지 자료형에 주의하여 문제 구성 필요
최적화 문제 유형의 구분
| 문제유형 | 정수 변수 없음 | 목적 함수에 2차항이 없음 | 제약조건에 2차항이 있음 |
|---|---|---|---|
| LP | O | O | |
| QP | O | X | |
| QCP | O | X | O |
| MILP | X | O | |
| MIQP | X | X | |
| MIQCP | X | X | O |
변수, 목적함수, 제약조건에 따라 문제 유형이 다르다. 문제 유형에 맞는 개발 환경구성이 필요하여 잘 못하면 처음부터 다시 구현해야 할 수도 있다.
| 선형계획법(Linear Programming) | 비선형계획법(QP, Non-LP) |
|---|---|
| 목적함수, 제약함수가 모두 1차식 결정변수가 모두 실수 가장 기본적인 문제 구조 |
목적함수, 제약함수 중 비선형 표현 n차 이상의 제곱식 등 가장 계산하기 어려운 문제 구조 |
| 많은 현실 문제는 비선형 | 풀이속도 느림, 수렴 어려움, 사악한 솔버 가격 |
| 오픈소스로 구현하기 쉬움 | 오픈소스로 구현하기 어려움 |
환경구성
파이썬 - 모델링 라이브러리 - 솔버(Solver)
- 모델링 라이브러리: 유저와 솔버간의 통역사. 유저가 정식화한 최적화 문제를 솔버 API로 연결 시켜주는 역할
- 솔버: 입력된 모델을 연산하여 결과 반환. 솔버 성능에 따라 최적 결과값이 다를 수 있다.
모델링 라이브러리
Matrix form: user가 직접 matrix형태로 조건, 함수등을 선언해준다.
효율적인 메모리 관리
다양한 개발환경
c = matrix ([2., 1.]) # 목적함수 A = matrix ([[1.], # 등식 제약조 [1.]])
Symbolic form: 함수 형태로 선언해줄 수 있다.
유지보수의 편리성
낮은 개발 난이도
# 문제유형 정의 prob = LpProblem("Simple LP", LpMinimize) # 변수 선언 x1 = LpVariable("x1", LowBound=0, upBound=None) x2 = LpVariable("x2", LowBound=0, upBound=None)
오픈소스마다 수식 표현 방법이 다르다. 문제의 크기가 작다면 Symbolic로 충분하지만 문제가 크다면 matrix로 가야한다.
모델링 라이브러리 비교(잘 모르겠다면 CVXPY 추천)
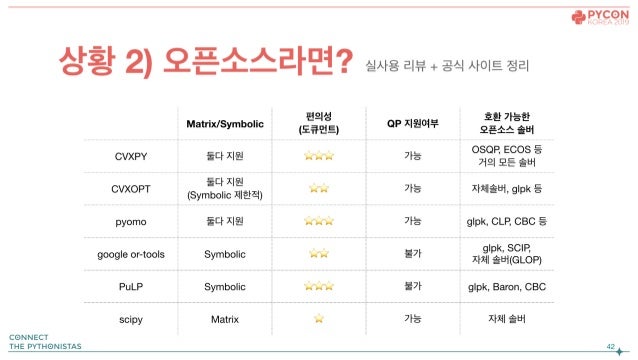
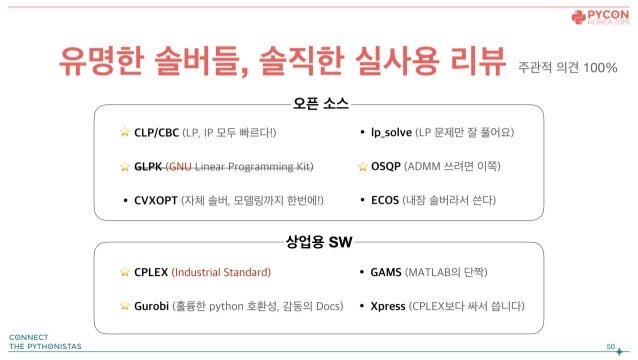
솔버
솔버 중 GNU 라이센스를 조심하자
- 예산의 제한이 없다면: CPLEX(압도적 속도 및 성능, 호환성과 도큐먼트에서 아쉬운 것이 없음)
- 학생이라면: 스트레스 없는 Gurobi or 오픈소스(Gurobi의 강력한 Academic License 지원)
- 스타트업이라면: 오픈소스
뚱뚱하고 굼뜬 판다스(Pandas)를 위한 효과적인 다이어트 전략 | 슬라이드
연사자 : 오성우
트랙 소개
판다스는 파이썬으로 데이터 분석을 한다는 사람은 모두가 알고 있는 대표적인 라이브러리입니다. 판다스는 인터페이스가 쉽고 메모리에 데이터를 올려두고 작업하는 방식이므로 처리 속도가 빠른 장점이 있다고 알려져있습니다.
하지만 실제 분석 현장과 연구에서 판다스를 이용해 데이터 처리와 분석을 하려고 했을 때, 예제보다는 용량이 큰 데이터에서 판다스가 그렇게 쉽고 빠르지만은 않다는 것을 경험하게 됩니다.
가끔은 컴퓨터가 터져버리는 것도 경험하게 됩니다. 어떤 다이어트를 하느냐에 따라서도 그 효과가 천차만별이듯이 판다스를 어떻게 사용하느냐에 따라서도 그 효과가 크게 달라집니다. 수백MB의 데이터가 수십MB의 메모리 사이즈로 줄어들기도 하고, 십분이 넘게 걸리던 처리작업이 단 몇초만에 끝나기도 합니다.
본 발표에서는 판다스를 사용하면서 자주 겪게 되는 두 가지 이슈 1)메모리 부족 문제, 2)긴 데이터 처리 시간 문제에 대한 해결 실마리를 함께 고민하는 자리가 되었으면 좋겠습니다. 지난 몇 년간 다양한 산업 영역의 프로젝트에 참여하면서 작게는 수십 메가바이트에서 크게는 테라바이트 단위의 데이터를 판다스로 처리하고 분석하면서 얻은 경험을 나누고자 합니다.
빠른 판다스 전략 1 - Memory Optimization
코드화: 문자열로 된 데이터를 숫자 or 영어로 변환하여 데이터 크기 축소 (4.49GB -> 1.7GB로 감소)
- 남자 -> 0 / 여자 -> 1
- 서울 -> 11 / 대구 -> 45
- 정상 0 -> 비정상 -> 1
데이터 형식 변환: 크기가 작은 데이터 형식 사용
아래 코드를 이용해서 각 칼럼에 딱 맞는 데이터 형식 부여
def reduce_mem_usage(df): start_mem = df.memory_usage().sum() / 1024**2 print('Memory usage of dataframe is {:.2f} MB'.format(start_mem)) for col in df.columns: col_type = df[col].dtype if col_type != object: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.uint8).min and c_max < np.iinfo(np.uint8).max: df[col] = df[col].astype(np.uint8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.uint16).min and c_max < np.iinfo(np.uint16).max: df[col] = df[col].astype(np.uint16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.uint32).min and c_max < np.iinfo(np.uint32).max: df[col] = df[col].astype(np.uint32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) elif c_min > np.iinfo(np.uint64).min and c_max < np.iinfo(np.uint64).max: df[col] = df[col].astype(np.uint64) else: if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) end_mem = df.memory_usage().sum() / 1024**2 print('Memory usage after optimization is: {:.2f} MB'.format(end_mem)) print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem)) return df
Category 데이터 형식 사용(8배 빨라짐)
특징
- Finite Value에 적합한 Data Type으로 Unique value가 반복해서 나타나는 경우 사용
- Int8로 데이터를 저장하고, Ordered와 Unordered 방식 모두 가능
한계
- 범주가 무수히 많은 경우 object보다 비효율적일 수 있음
# Object t20['MAIN_SICEK'] = t20['MAIN_SICEK'].astype('object') #Category t20['MAIN_SICEK'] = t20['MAIN_SICEK'].astype('category')
파일 저장 포맷 변경
- 개인적 사용 목적: feather, pickle
- 프로젝트, 협업 목적: parquet, hdf5
빠른 판다스 전략2 - Enhancing Performance
Vectorization
pd.apply--> 2분33초
vectorization with pandas series --> 2.3초
vectorization with numpy array--> 0.7초
명시적으로 반복문을 사용하지 않고도 배열의 모든 원소에 대해 반복연산이 가능하다.
def scoring_health(patient): waist = (patient.WAIST >= 90) * 1 drink = (patient.DRINK == 1) * 1 chole = (patient.TOT_CHOLE >= 130) * 1 return np.sum([waist, dirnk, chole], axis=0)
np.vectorize: Custom 함수의 vectorization을 쉽게 도와주는 Numpy 함수
def func(a, b): return a * b np_func = np.vectorize(func)
Considering Efficient Algorithm
급여비용이 높았던 진료내역 상위 5개 추출 예시
# run time: 7.81 s t20.EDEC_TRAMT.sort_values(ascending=False).head(5) # run time: 683 ms t20.EDEC_TRAMT.nlargest(5)
pd.apply() ???
- 많은 경우에 Custom 함수를 만들어 apply를 사용한다. 대부분 원하는 대로 작동하며 Lambda 함수와 함께 많이 사용 된다. 수행 시간이 오래 걸릴 경우 적절한 pd built-in 함수를 찾아 조합하여 사용하여아 한다.
| 방법 | 코드 | 수행시간 |
|---|---|---|
| List Comprehension | df[[x in patients for x in df.PATIENT_ID]] | 6 m 21 s |
| pd.Series.apply | df[df.PATIENT_ID.apply(lambda x: x in patients)] | 6 m 26 s |
| pd.DataFrame.isin() | df[df.isin({'PATIENT_ID' : patients}).PATIENT_ID] | 11.3 s |
| pd.DataFrame.query() | df.query('PATIENT_ID in @patients') | 6.2 s |
| np.isin() | df[np.isin(df.PATIENT_ID, patients)] | 5.1 s |
| pd.DataFrame.merge() | df.merge(patients, how='inner', on='PATIENT_ID') | 3.6 s |
빠른 판다스 전략3 - Adopting Conventions
목표
- Pandas에도 pep8처럼 coding convention들이 있음을 소개(ver 1.0을 향해 나아가는 중)
Method Chaining
가독성과 성능이 좋아짐
하지만 DataFrame의 중간체크가 어려우며 진짜 성능이 좋아지는지 물음표
# 일반적인 방법 jack_jill = JackAndJill() on_hill = went_up(jack_jill, 'hill') with_water = fetch(on_hill, 'water') fallen = fell_down(with_water, 'jack') # Method Chaining jack_jill = JackAndJill() fallen = ( jack_jill .went_up("hill") .fetch("water") .fell_down('jack') )
inplace parameter
- "inplace"는 결과를 바로 해당 df에 덮어씌우고 싶을 때 사용한다.
- inplace를 선호하는 사용자들의 의견: 속도가 더 빠르다 / 메모리를 더 효율적으로 사용한다. 하지만 Pandas Core 개발자들은 이에 반대하고 있으며 inplace에 대한 deprecation 및 삭제를 논의중이며 Method Chaining 방식을 적극 권장하고 있다. 이유는 inplace 이후에도 메모리에 데이터가 남아있는 문제가 자주 있어서.
어떤 식으로 구분해서 사용하는 것이 좋은가
- Method Chaining
- 결과 DataFrame의 전체를 생성하고 재할당(reassign)하는 특징
- chaining 과정에서 데이터 크기가 줄어들 때 메모리 효율적
- 따라서 .drop(), .astype() 등을 우선적으로 사용하는 것이 좋음
- inplace parameter
- 추상화된 함수 내부에서 df의 일부만 생성되어 재할당 되는 특징
- 큰 작업 단위에서 Method Changing 보다 성능, 메모리 사용에서 종종 우위를 보임
- 따라서 .set_index(), .rename()과 같이 일부 내용만 변경하는 경우에 효율적
- Method Chaining
Deprecations
- .ix와 같은 오래전부터 deprecation으로 등록되어 있는 것들은 Pandas 1.0에서 모두 삭제될 것이라 밝힘
- padnas 0.25.x까지는 사용 가능
판다스로 적절한 데이터 크기는??
| > 5GB | 5GB ~ 100GB | 100GB < |
|---|---|---|
| 어떤 방법으로도 빠르게 수행 | 10 ~ 30GB부터 Performance 저하 시작 | 개인 데스크탑으로는 한번에 처리하기 어려워 지기 시작, 다이어트 전략 효과도 감소 |
Pickle & Custom Binary Serializer | 슬라이드
연사자 : 김용석
트랙 소개
- What is serialization? Explain motivation & purpose + examples (ex: caching)
- Differences between other serialization methods (for example, JSON)
- Introduce Pickle 1. Practical Use cases - ex) CSV reading vs Pickled Dictionary, Program State Persistence, Sending Python objects over a TCP connection 2. Five Different Pickle protocols (summary) 3. Differences between pickle protocols (ablation table) 4. Pickle Implementation
- When to / When not to use pickle
- A personal story about implementing custom binary serializer for implementing a compressed neural network
- Brief tutorial to implement custom binary serializer
- Security warning about pickle / Takeaway points (Talk summary with bullet points)
What is Pickle? What is serialization?
- pickle module를 이용하여 Serialization 관련 작업을 할 수 있다.
| pickle.dump() | pickle.load() | |||
|---|---|---|---|---|
| Python Object | Serialization | 011001011... | De-Serialization | Python Object |
- Other serialization methods
| Pickle | Json | Protpbuf | MessagePack | |
|---|---|---|---|---|
| Human-readable | No(except protocol 0) | Yes | No | No |
| Python-specific | Yes | No | No | No |
| User-defined class | Yes | No | No | No |
Pickle은 dump시에 protocol을 지정해줄 수 있다.
pickle.dump(obj, file, protocol=None, *, fix_imports=True)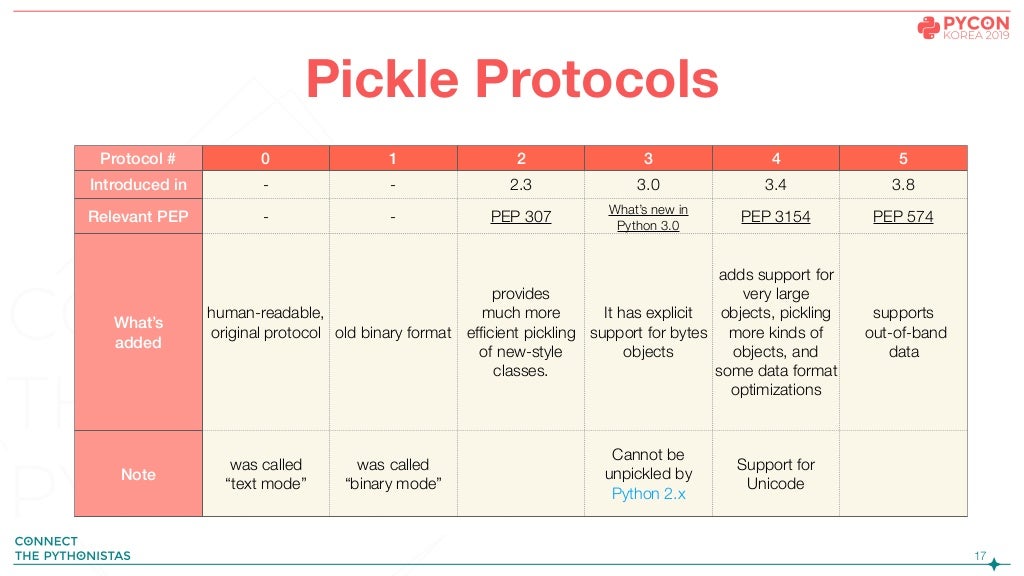
각 protocol에 따라 serialzation 방식이 달라지는데 이에 대한 자세한 설명은 본 트랙의 슬라이드를 직접 참고하는 것이 좋을 듯 하다.(md로 쓰기엔 너무 길며 꼭 알아야 할 부분은 아니다.)
What can be pickled and unpickled?
- None, True, False
- intergers, floating point numbers, complex numbers
- strings, bytes, bytearrays
- tuples, lists, sets, dictionaries containing only picklable objects
- Classes, functions(both built-in and user-defined) defined at the top level of a module(using def, note lambda)
- Instances of such classes whose
__dict__or the result of calling__getstat__()is picklable(see section Pickling Class instances for details)
Can a function be pickled?
결과부터 말하면 할 수 없다. 오로지 functions's name만 pickled할 수 있다. 이것은 lambda functions를 pickled할 수 없다 로 연결이 된다. 비슷하게, classes, methods도 마찬가지.
def hello():
print("hi")
import pickle
# hello()를 pickle로 저장
with open('func.pickle', 'wb') as f:
pickle.dump(hello, f)import pickle
with open('func.pickle', 'rb') as f:
a = pickle.load(f)
# 저장한 hello()를 불러오려 했으나 에러발생
>>> Can not get attribute 'hello' on <module '__main__'>def hello():
print('hello')
with open('func.pickle', 'rb') as f:
a = pickle.load(f)
a()
# 처음에 저장했던 "hi"를 출력하는 hello()가 아닌 새로 선언한 동명 hello()의 기능을 수행함을 볼 수 있음
>>> hello100억건의 카카오톡 데이터로 똑똑한 일상대화 인공지능 만들기 | 슬라이드
연사자 : 김준성 현)스캐터랩
트랙소개
100억 건의 카카오톡 데이터로 어떻게 똑똑하고 생동감 넘치는 인공지능을 만들었는지 공유하는 세션입니다. 인공지능을 위한 일상대화 기술인 '핑퐁'을 소개하고, 핑퐁을 만드는 과정에서 사용한 NLU 엔진과 다양한 답변 생성 기술을 소개합니다. 마지막에는 대화의 문맥과 의미를 정확하게 잡아내는 모델의 결과를 공유합니다.
NLU(Natural Language Understanding)
NLU 란 한글로 "자연어 이해"에 해당된다. 자연어 표현을 기계가 이해할 수 있는 다른 표현으로 변환시키는 것을 뜻한다.
2018.10까지의 NLU 연구
- Word2Vec(단어 단위 Representation): 주변 단어들간의 위치를 활용하여 Skip-Gram 방식으로 학습한다.
- ELMo(문장 단위 Representation): BI-LSTM 모델구조를 이용해 다음 단어를 예측하도록 학습한다.
이때까지는 각 문장에 대해 깊게 이해하지 못하고, 문장이 길수록 이해도가 급격하게 떨어졌다. 또한 대화의 문맥(Dialog-Context)은 전혀 이해하지 못했다. 그러던 중 BERT(Bidirectional Encoder Representation from Transformer)이 등장한다. 등장하자마자 사람의 이해력을 넘었으며 11개의 NLP 테스크에서 SOTA(State-Of-The-Art)를 기록한다. 그래서 대화체에 BERT를 적용해보기로 했다.
대화체 NLU 모델로 BERT를 사용하게 되면 얻는 이점
- Self-Attention을 여러 층 쌓게 되면 더 복잡한 상관관계 즉 깊은 이해가 가능함
- 단어들의 관계를 종합적으로 여러번 보기 때문에 용언이나 체언에 민감x
- 긴 문장에도 유연해서 대화의 문맥 정보 역시 효과적으로 이해할 수 있음
- Masked LM 이라는 간단한 방식의 언어 이해 / 하지만 깊은 이해
- Next Sentence Prediction 모델을 통해서 문맥에 대한 이해 추가
Dialog-BERT 학습 방법
1. 빈칸 맞추기 문제: Masked Language Modeling
전체 단어에서 15%를 랜덤삭제 후 해당 위치의 원래 단어 맞추기 -> 전체 대화 문맥과 해당 대화의 주변 단어들간의 관계를 유추해서 맞춰야 함.
| 이번주 파이콘 가냥? 가쉴? | 이번주 파이콘 가냥? 가쉴? |
|---|---|
| 엥 너도 가냐? 오키 기기 | 엥? 너도 가냐? [MASK] 기기 |
| 이번에 재밌는 거 많던데 | 이번에 [MASK] 거 많던데 |
| 난 준성님 발표 들을꺼 ㅋㅋ | 난 준성님 발표 [MASK] ㅋㅋ |
2. 연속 대화 여부 Classification: Next Sentence Prediction
현재 문맥에서 주어진 다음 문장이 이어질 수 있는지 학습하는 방식. 이를 통해 연속된 대화에서 자연스러운 문맥이 무엇인지 자연스럽게 이해함
| 문맥에 맞는 대답-Target 1 | 문맥에 맞지 않는 대답-Target 0 | |
|---|---|---|
| A: 이번에 핑클 새 뮤비 봄? B: 당근 와 진짜 대박이더라 A: 그니까 ㅠㅠ 이번 노래 최고야 진짜 |
그래서 이번에 앨범 사려고!! | 점심 먹은거 어머니께 말씀 드렸어? |
3. 대화시스템에 맞는 BERT 구조변경
기존 모델에는 각 턴을 구분할 수 있는 정보가 없어서 턴을 구분하기 어려웠음. Dialog-BERT에서는 Turn Embedding을 추가해 각 턴별 정보를 넣었음.
위 말을 풀어보자면...
- 기존 방법: [CLS] 문장 1 [SEP] 문장2 [SEP]
- Turn 정보 추가: [CLS] 턴1_문장1 [SEPT] 턴2_문장1 [SEPT] 턴3_문장1 [SEP] 문장2 [SEP]
4. 모델의 학습
- google-research/bert 레포를 이용하여 학습.
- 풍부한 대화를 하는 사용자를 골라 10억건의 대화 데이터 사용
- Google TPU-v3를 사용하여 약 18일간 학습
- Next Sentence Prediction: 88.4% ACC
- Masked Language Modeling: 53.6% ACC
- 이는 타 모델에 비해 이해력이 매우 우수하다는 결과
Model을 활용해보자
뛰어난 이해력을 무기로 갖추었으니 이제 말을 할 수 있도록 가르쳐 보자. Real world에선 input은 무한한 경우의 수를 가지고 있으며 output도 그러하다. 그럼 만약 output를 유한개로 줄일 수 있다면?
무한개의 질문들에 대해 유한개의 답변이 얼마나 수많은 질문을 얼마나 적절한 답변으로 커버할 수 있는지 여부부터 살펴보아야 한다. 실제 대화 데이터를 뒤져서 대화 커버리지를 극대화 할 수 있는 답변들을 찾아보았다. 대화 메시지 빈도수 기준으로 리액션에 가까운 말들이 상위를 랭크했다. Top 1만개 문장이 전체 8000만개 메시지중 21.87%(1700만번)를 차지했음.
ex) 알겠어요, 귀여워, 거짓말, 잘자요, 어딘데, 잘했어요, 대박, 많이 먹었어?, 맛있게먹어, 미안해요, 아니에요, 부러워, 졸려, 밥먹었어?, 진짜요?, 사랑해요, 괜찮아, 누구랑?, 언제?, 신기해, 나도나도, 아직도?
이에 착안하여 리액션 모델을 만든다면 기존 시스템들에 비해 Query Coverage를 크게 늘릴 수 있을거라는 아이디어 도출. 사용자의 무한한 질문에 어쩔 줄 몰라하던 봇이 이제 어느 정도 맞받아 칠 수 있는 능력을 가질 것으로 기대.
그래서 상위 답변을 Reaction Class로 만들고, 분류 문제로 풀어봄. 약 5턴 정도의 문맥을 input으로 주고, 어떤 리액션을 사용할지 예측하도록 학습시켜 봄
| 어제 만들던거 다 함? | 아직요 | 헐 아직도.. | 네.. | 이제 좀 자 | 알겠어요 |
|---|---|
| 쌤 이거 어케 한다구요? | 종이에 써놓음 | 봇 이거 쓰면 되죠? | 응 그럴거야 | 알겠어요 |
| 아 정신이 없다 | 아 진짜 | 아 진짜 배고프다 | 나도 |
| 요즘 피곤해보여 | 요즘 계속 야근해서 | 가끔 중간에 좀 자고 싶어 | 나도 |
| 언제옴? | 12시쯤? | 헉 늦네 배고프겠다 | 응 진짜 ㅠㅠ | 야식 먹을까? | 좋아! |
Pytorch를 이용한 Fine-Tuning
- HuggingFace의 Pytorch-Transformer 라이브러리 이용
- 학습된 NLU 모델을 활용한 개발 / 학습 with pytorch
- 리액션 모델의 fine-tuning 조정 학습 과정 하루정도 소모 use V100 GPU
- 결과
- 기존 봇이라면 if로 처리했어야 할 것을 유연하게 대처 가능
- 어제 여친이랑 헤어짐 -> 어쩌다가요
- 나 어제 고백받음 -> 누구한테요?
- 사회적인 개념에 대해 이해함
- 오늘 월요일이다 -> 알아요
- 오늘 금요일이다 -> 좋아요?
- 긴 문장도 잘 이해하고, 구체적 질문이나 답변 가능
- 어제 엄청 늦게 잤더니 늦게 일어나서 아침 못먹고 나옴 -> 몇시에 잤는데요?
- 어제 술 너무 많이 마셨어 ㅠㅠ -> 많이 마셨어요?
- 문맥을 이해하는 답변
- 마지막 대화를 "그럴까?"로 마무리 해도 앞의 문맥에 따라 "같이 갈래요?", "피곤하면 자야죠" 등으로 답변이 달라짐
- 기존 봇이라면 if로 처리했어야 할 것을 유연하게 대처 가능
라이트닝 톡
왜 사람들은 회사 냉장고에 음식 넣을때 스티커를 붙이지 않는가?
기본적으로 사용자는 매우 게으른 사람이다. 그래서 사용자가 일을 하게 하기 위해선 그 일의 프로세스가 매우 효율적이여야 한다.
기존 프로세스
- 펜을 꺼냄
- 스티커에 이름, 유통기한을 씀(정말 귀찮음)
- 스티커를 땜(잘 안떨어짐)
- 스티커를 음식에 붙임
변경 프로세스
- nfc를 라즈베리파이에 tag -> 이름과 유통기한이 명시되어 스티커 기계에서 때기 쉬운 형태로 출력
- 스티커를 음식에 붙임
멋쟁이사자에서 교육장을 한 경험
스터디그룹 30명 중 전공자는 발표자 혼자. 나머지 다 비전공자. 이 상황에서 교육을 효율적으로 잘 하기 위해 3가지 방법을 도입해봄
- 의사소통은 슬랙을 통해서 -> 절반정도 지켜짐. 사람들이 슬랙을 곧바로 잘 사용하지 않아서 슬랙에 글을 올리고 카톡 단체방에서 슬랙 공지 확인 요청글을 올리기도 함
- Flipped learning -> 실패함. 각자 영상으로 공부 후 다 같이 모여 퀴즈를 풀고 스터디 하는 방식. 하지만 영상을 안보고 오는 경우가 많고, 영상 속 퀴즈를 그대로 내도 못푸는 경우가 많음
- Project base learning -> 성공함. 작품을 제작하며 배워서 스터디원들의 흥미가 높음
파이썬으로 작심30일
- 1일 1커밋 계획을 세움
- 계획을 미시행시 벌금을 걷어 기부함.
- 정말 단순히 변수 명 바꾸는 것만으로도 인정. 깃허브에 접속 했다는 사실이 중요한 것
- 이렇게 꾸준히 점진적으로 습관을 만들어주어야함
- 작심30일 이후 습관의 관성으로 다시 옛날로 돌아감..계속 꾸준히 해야 할 필요성을 느낌
파이썬으로 로봇하기
로봇은 두개의 컴포넌트로 나눌 수 있다. H/W와 S/W. 파이썬으로 로봇을 하면 쉽게 접근할 수 있는 장점이 있다. 관련된 package로 Pytobot(초급), Ros(고급)이 있다. 지식은 facebook Ai robotics group에서 쌓을 수 있다.
테스트에 걸리는 시간을 92% 줄이기 | 슬라이드
create user account test에서 100개 생성당 20초가 걸렸다.
- user account 100개 생성에 20초가 걸림
- 알아보니 비밀번호 해시처리가 느려서
- 이유는 키 스트레칭(pw가 맞는지 확인하는 데 약. 0.2초 이상 걸리게 하는 것) 때문
- Django는 계정생성시 옵션을 주지 않는 한 defaul 옵션인 느린 FBKDF2_SHA256 사용
- 그래서 비밀번호 해시 알고리즘을 매우 빠르지만 취약한 MD5로 변경.
- 런타임 20.490s -> 0.034
Mocking & freezegun
- 메소드 호출에 대해 고정된 응답을 반환하고(Mocks)
- 실제 객체처럼 동작하며(Stubs)
- 함수 호출 파라미터, 리턴 값 등을 검증하는 (Spies) 객체!
쉽게 풀어보자면, 테스트 코드를 작성하다보면 가끔은 실제로 실행할 수 없는 코드들을 마주하게 된다. 예를 들어 SMS API를 호출하여 문자를 발송한다던지, 결제 API를 사용해서 결제를 한다던지 말이다. 이러한 외부 API를 테스트 코드에서 호출하게 되면 실제로 API가 작동해버릴 수 있으니 조심해야한다. 하지만 이러한 응답값에 대해 로직을 테스트하고 싶을 땐 어떻게 해야할까. Mocking 이 그 해결책이다.
사례: API 쓰로틀링 로직
대량으로 호출해야하는 외부 API에 쓰로틀링을 걸어야 하는 경우가 있다. 이때 time.sleep를 사용하면 테스트 환경에서는 시간만 소모하는 원인이 된다. 이때, mocking와 freezegun을 이용하여 정말 time.sleep한 것 처럼 속일 수 있다.
from freezegun import freeze_time
from unittest.mock import patch
def do_some_big_thing():
do_something()
time.sleep(10)
# mock.patch: 런타임에 메서드나 변수를 추가하거나 변경하는 것
@mock.patch('some_module.time.sleep')
# some_module.time.sleep 대신 sleep_mock이 호출 됨
def test_logic_sleep(self, sleep_mock):
# freeze_time 호출하면 내부적으로 datetime 모듈을 override 해둠
# datetime.datetime.now와 같은 함수 호출시 내가 지정한 날짜를 돌려주도록 만듦
with freeze_time as fozen_time:
sleep_mock.side_effect =\
lambda s: frozen_time.tick(datetime.timedelta(secounds=3))
start = datetime.datetime.now()
do_some_big_thing()
self.assertGreaterEqual((end - start).seconds, 10)테스트는 다른 테스트에 영향 받지 않아야 한다.
test case에서 생성한 데이터 삭제가 필요한 경우.
쟝고에서는 DB데이터를 삭제하는 동일한 로직을 2가지 방법으로 구현해 놓음
- Test case: 클래스와 테스트 함수를 시작할 때 각각 트랜잭션으로 감쌈
class Test_something(TastCase): # begin transaction def test_1(self): # save point s1 pass # rollback to save point s1 def test_2(self): # # save point s2 pass # rollback to save point s2 #rollback- Transaction test case: 테스트가 끝날때마다 TRUNCATE TABLE 사용하여 데이터 삭제
class Test_something(TransactionTestCase): def test_1(self): pass # TRUNCATE TABLE A; *Table 수 def test_2(self): pass # TRUNCATE TABLE A; *Table 수Performance
- test env : 230개 테이블, MySQL 5.7
- Test case: 1600개 테스트 케이스 수행시 롤백에 걸리는 시간 0.928s
- transaction test case: 1600개 테스트 케이스 수행시 롤백에 걸리는 시간 46m 1s
on_commit
예외가 발생해서 트랜잭션이 롤백되면 문자메시지도 전송되지 않음
@transaction.atomic
def do_important_thing():
transaction.on_commit(lambda: send_sms('important sms'))Disable linter
Linter: 코딩 컨밴션과 에러를 체크해주는 툴이지만 경험상 대략 30%정도 느려짐. 코드 퀄리티를 생각한다면 lint 및 커버리지 확인 툴을 항상 켜야하나 테스트 시간이 오래 걸리는 것은 트레이드 오프. 그래서 아래와 같이 적용하였다.
- 개발자가 기다리는 상황: PR/ Push 등의 이벤트에선 Lint 해제
- 개발자가 자는 상황: 일일 새벽 정기 빌드 등 Lint 및 커버리지 테스트 추가